perfのつかいかた
Linux perfでのパフォーマンス分析のやり方。branch-missやキャッシュミス分析まで
Rob pikeの有名な言葉の通り、パフォーマンスの定量的な計測(そして定性的な分析)はソフトウェアを書く上で重要だ。
準備
releaseビルドしてインライン化されていてもDWARFを使って解析が出来るが、そもそもデバッグ情報なしだとまともに動かない。releaseプロファイルでもdebugを有効化するか、丁寧にやるなら別途profileを作る。profile.release.package.*でも指定する。
[profile.release]
debug = true
[profile.release.package."*"]
debug = true
debuginfo = 2
計測と分析
以下のコマンドで実行。-Fでサンプリング周期を変えても良い。あまりに長時間やると巨大なファイルになるので注意。--call-graph dwarfをつける。/proc/kallsymsが見えずカーネル内部の情報が取れないのでrootの方が良い。
TUIで分析
sudo env PATH="$PATH:/home/namachan10777/.cargo/bin" perf report
sudo perf script report flamegraph
また、/usr/libexec/perf-core/以下にLinuxのtools/perf/scriptsディレクトリをコピーしておくとperf script report flamegraphでflamegraph.htmlが生成される。カーネルランドとユーザランドが色分けされるのもあり、Brendan Gregg先生のスクリプトより若干便利。

これは2スレッドなので2つ塊が出来る。自作ランタイム上でのRPCを分析したものだが、bincodeのdecodeがやたら重いことが読み取れる。
より詳細な情報についてはperfのannotateを使う。perf reportで開いて関数をannotateするのが便利。
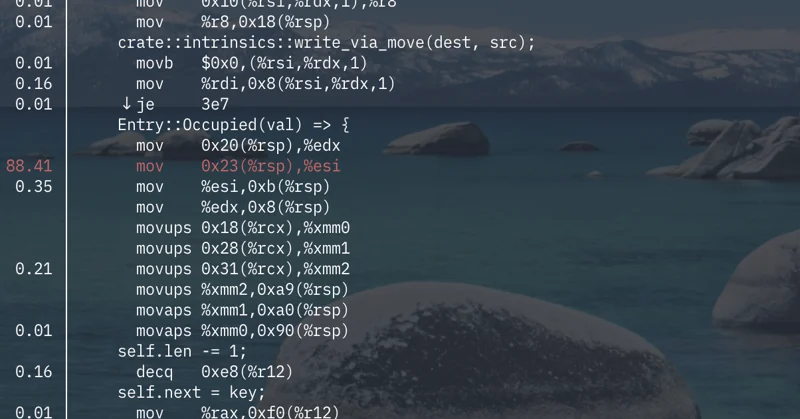
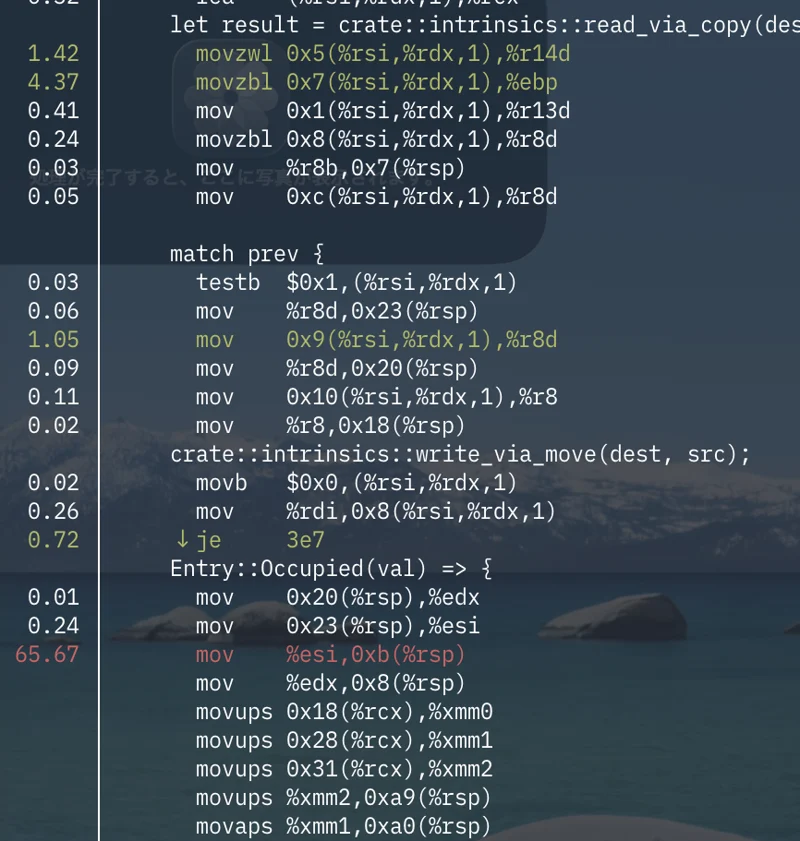
とりあえずmovが遅いらしい。ただし、命令、特にメモリアクセス命令というのは単純に一律で実行時間がかかるものではない(その下のコピー命令が軽いことからも分かる)。おそらくはこの辺りでL1キャッシュをミスしてpipeline stallが起きている可能性がある。esiレジスタがすぐ次の命令で使われていることもこの推測を補強する。:ppをつけておくとskidを防いで正確性が増す。
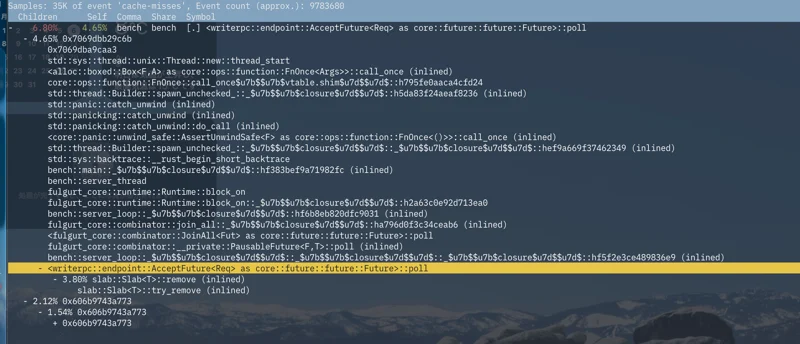
あれ?そこまで高わけでもなさそう。
分岐予測も実は割とミスってる。が、実はVecDequeはもっとミスってる。つまり痛くはあるがそこまで時間がかかるわけではない。
まとめ
perfは単にflamegraphを取るだけのツールではなく、cache missや分岐予測ミスも収集出来る。
コメント
コメントはまだありません